 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo All Individual Layers Help? An Empirical Study of Task-Interfering Layers in Vision-Language Models
Feb 01, 2026Current VLMs have demonstrated capabilities across a wide range of multimodal tasks. Typically, in a pretrained VLM, all layers are engaged by default to make predictions on downstream tasks. We find that intervening on a single layer, such as by zeroing its parameters, can improve the performance on certain tasks, indicating that some layers hinder rather than help downstream tasks. We systematically investigate how individual layers influence different tasks via layer intervention. Specifically, we measure the change in performance relative to the base model after intervening on each layer and observe improvements when bypassing specific layers. This improvement can be generalizable across models and datasets, indicating the presence of Task-Interfering Layers that harm downstream tasks' performance. We introduce Task-Layer Interaction Vector, which quantifies the effect of intervening on each layer of a VLM given a task. These task-interfering layers exhibit task-specific sensitivity patterns: tasks requiring similar capabilities show consistent response trends under layer interventions, as evidenced by the high similarity in their task-layer interaction vectors. Inspired by these findings, we propose TaLo (Task-Adaptive Layer Knockout), a training-free, test-time adaptation method that dynamically identifies and bypasses the most interfering layer for a given task. Without parameter updates, TaLo improves performance across various models and datasets, including boosting Qwen-VL's accuracy on the Maps task in ScienceQA by up to 16.6%. Our work reveals an unexpected form of modularity in pretrained VLMs and provides a plug-and-play, training-free mechanism to unlock hidden capabilities at inference time. The source code will be publicly available.
Learning to Accelerate Vision-Language-Action Models through Adaptive Visual Token Caching
Jan 31, 2026Vision-Language-Action (VLA) models have demonstrated remarkable generalization capabilities in robotic manipulation tasks, yet their substantial computational overhead remains a critical obstacle to real-world deployment. Improving inference efficiency is therefore essential for practical robotic applications. Existing acceleration methods often rely on heuristic or static strategies--such as rule-based token caching or pruning--that are decoupled from task objectives and fail to adapt to dynamic scene changes. In this work, we reformulate inference acceleration as a learnable policy optimization problem and propose a novel framework that integrates a dynamic, task-aware decision-making process directly into the VLA model. At its core are two lightweight, cooperative modules: a Cached Token Selector, which determines which tokens should be reused, and a Cache Ratio Predictor, which controls how many tokens to reuse. Training these modules is non-trivial due to their discrete decisions. We address this by adopting a differentiable relaxation that allows gradient-based end-to-end optimization. Extensive experiments on the LIBERO and SIMPLER benchmarks, as well as real-robot evaluations, show that our method achieves a 1.76x wall-clock inference speedup while simultaneously improving the average success rate by 1.9 percentage points (from 75.0% to 76.9%) on LIBERO and by 5.0 percentage points on real-world tasks, significantly outperforming existing baselines. This work highlights the potential of learning task-aware computational allocation policies, paving the way for VLA models that are both powerful and efficient.
Inject Once Survive Later: Backdooring Vision-Language-Action Models to Persist Through Downstream Fine-tuning
Jan 31, 2026Vision-Language-Action (VLA) models have become foundational to modern embodied AI systems. By integrating visual perception, language understanding, and action planning, they enable general-purpose task execution across diverse environments. Despite their importance, the security of VLA models remains underexplored -- particularly in the context of backdoor attacks, which pose realistic threats in physical-world deployments. While recent methods attempt to inject backdoors into VLA models, these backdoors are easily erased during downstream adaptation, as user-side fine-tuning with clean data significantly alters model parameters, rendering them impractical for real-world applications. To address these challenges, we propose INFUSE (INjection into Fine-tUne-inSensitive modulEs), the first backdoor attack framework for VLA base models that remains effective even with arbitrary user fine-tuning. INFUSE begins by analyzing parameter sensitivity across diverse fine-tuning scenarios to identify modules that remain largely unchanged -- the fine-tune-insensitive modules. It then injects backdoors into these stable modules while freezing the rest, ensuring malicious behavior persists after extensive user fine-tuning. Comprehensive experiments across multiple VLA architectures demonstrate INFUSE's effectiveness. After user-side fine-tuning, INFUSE maintains mean attack success rates of 91.0% on simulation environments and 79.8% on real-world robot tasks, substantially surpassing BadVLA (38.8% and 36.6%, respectively), while preserving clean-task performance comparable to standard models. These results uncover a critical threat: backdoors implanted before distribution can persist through fine-tuning and remain effective at deployment.
Dynamic Differential Linear Attention: Enhancing Linear Diffusion Transformer for High-Quality Image Generation
Jan 20, 2026Diffusion transformers (DiTs) have emerged as a powerful architecture for high-fidelity image generation, yet the quadratic cost of self-attention poses a major scalability bottleneck. To address this, linear attention mechanisms have been adopted to reduce computational cost; unfortunately, the resulting linear diffusion transformers (LiTs) models often come at the expense of generative performance, frequently producing over-smoothed attention weights that limit expressiveness. In this work, we introduce Dynamic Differential Linear Attention (DyDiLA), a novel linear attention formulation that enhances the effectiveness of LiTs by mitigating the oversmoothing issue and improving generation quality. Specifically, the novelty of DyDiLA lies in three key designs: (i) dynamic projection module, which facilitates the decoupling of token representations by learning with dynamically assigned knowledge; (ii) dynamic measure kernel, which provides a better similarity measurement to capture fine-grained semantic distinctions between tokens by dynamically assigning kernel functions for token processing; and (iii) token differential operator, which enables more robust query-to-key retrieval by calculating the differences between the tokens and their corresponding information redundancy produced by dynamic measure kernel. To capitalize on DyDiLA, we introduce a refined LiT, termed DyDi-LiT, that systematically incorporates our advancements. Extensive experiments show that DyDi-LiT consistently outperforms current state-of-the-art (SOTA) models across multiple metrics, underscoring its strong practical potential.
ReViSE: Towards Reason-Informed Video Editing in Unified Models with Self-Reflective Learning
Dec 11, 2025



Video unified models exhibit strong capabilities in understanding and generation, yet they struggle with reason-informed visual editing even when equipped with powerful internal vision-language models (VLMs). We attribute this gap to two factors: 1) existing datasets are inadequate for training and evaluating reasoning-aware video editing, and 2) an inherent disconnect between the models' reasoning and editing capabilities, which prevents the rich understanding from effectively instructing the editing process. Bridging this gap requires an integrated framework that connects reasoning with visual transformation. To address this gap, we introduce the Reason-Informed Video Editing (RVE) task, which requires reasoning about physical plausibility and causal dynamics during editing. To support systematic evaluation, we construct RVE-Bench, a comprehensive benchmark with two complementary subsets: Reasoning-Informed Video Editing and In-Context Video Generation. These subsets cover diverse reasoning dimensions and real-world editing scenarios. Building upon this foundation, we propose the ReViSE, a Self-Reflective Reasoning (SRF) framework that unifies generation and evaluation within a single architecture. The model's internal VLM provides intrinsic feedback by assessing whether the edited video logically satisfies the given instruction. The differential feedback that refines the generator's reasoning behavior during training. Extensive experiments on RVE-Bench demonstrate that ReViSE significantly enhances editing accuracy and visual fidelity, achieving a 32% improvement of the Overall score in the reasoning-informed video editing subset over state-of-the-art methods.
Taming Consistency Distillation for Accelerated Human Image Animation
Apr 15, 2025Recent advancements in human image animation have been propelled by video diffusion models, yet their reliance on numerous iterative denoising steps results in high inference costs and slow speeds. An intuitive solution involves adopting consistency models, which serve as an effective acceleration paradigm through consistency distillation. However, simply employing this strategy in human image animation often leads to quality decline, including visual blurring, motion degradation, and facial distortion, particularly in dynamic regions. In this paper, we propose the DanceLCM approach complemented by several enhancements to improve visual quality and motion continuity at low-step regime: (1) segmented consistency distillation with an auxiliary light-weight head to incorporate supervision from real video latents, mitigating cumulative errors resulting from single full-trajectory generation; (2) a motion-focused loss to centre on motion regions, and explicit injection of facial fidelity features to improve face authenticity. Extensive qualitative and quantitative experiments demonstrate that DanceLCM achieves results comparable to state-of-the-art video diffusion models with a mere 2-4 inference steps, significantly reducing the inference burden without compromising video quality. The code and models will be made publicly available.
DreamRelation: Relation-Centric Video Customization
Mar 10, 2025Relational video customization refers to the creation of personalized videos that depict user-specified relations between two subjects, a crucial task for comprehending real-world visual content. While existing methods can personalize subject appearances and motions, they still struggle with complex relational video customization, where precise relational modeling and high generalization across subject categories are essential. The primary challenge arises from the intricate spatial arrangements, layout variations, and nuanced temporal dynamics inherent in relations; consequently, current models tend to overemphasize irrelevant visual details rather than capturing meaningful interactions. To address these challenges, we propose DreamRelation, a novel approach that personalizes relations through a small set of exemplar videos, leveraging two key components: Relational Decoupling Learning and Relational Dynamics Enhancement. First, in Relational Decoupling Learning, we disentangle relations from subject appearances using relation LoRA triplet and hybrid mask training strategy, ensuring better generalization across diverse relationships. Furthermore, we determine the optimal design of relation LoRA triplet by analyzing the distinct roles of the query, key, and value features within MM-DiT's attention mechanism, making DreamRelation the first relational video generation framework with explainable components. Second, in Relational Dynamics Enhancement, we introduce space-time relational contrastive loss, which prioritizes relational dynamics while minimizing the reliance on detailed subject appearances. Extensive experiments demonstrate that DreamRelation outperforms state-of-the-art methods in relational video customization. Code and models will be made publicly available.
FreeScale: Unleashing the Resolution of Diffusion Models via Tuning-Free Scale Fusion
Dec 12, 2024



Visual diffusion models achieve remarkable progress, yet they are typically trained at limited resolutions due to the lack of high-resolution data and constrained computation resources, hampering their ability to generate high-fidelity images or videos at higher resolutions. Recent efforts have explored tuning-free strategies to exhibit the untapped potential higher-resolution visual generation of pre-trained models. However, these methods are still prone to producing low-quality visual content with repetitive patterns. The key obstacle lies in the inevitable increase in high-frequency information when the model generates visual content exceeding its training resolution, leading to undesirable repetitive patterns deriving from the accumulated errors. To tackle this challenge, we propose FreeScale, a tuning-free inference paradigm to enable higher-resolution visual generation via scale fusion. Specifically, FreeScale processes information from different receptive scales and then fuses it by extracting desired frequency components. Extensive experiments validate the superiority of our paradigm in extending the capabilities of higher-resolution visual generation for both image and video models. Notably, compared with the previous best-performing method, FreeScale unlocks the generation of 8k-resolution images for the first time.
Timestep Embedding Tells: It's Time to Cache for Video Diffusion Model
Nov 28, 2024



As a fundamental backbone for video generation, diffusion models are challenged by low inference speed due to the sequential nature of denoising. Previous methods speed up the models by caching and reusing model outputs at uniformly selected timesteps. However, such a strategy neglects the fact that differences among model outputs are not uniform across timesteps, which hinders selecting the appropriate model outputs to cache, leading to a poor balance between inference efficiency and visual quality. In this study, we introduce Timestep Embedding Aware Cache (TeaCache), a training-free caching approach that estimates and leverages the fluctuating differences among model outputs across timesteps. Rather than directly using the time-consuming model outputs, TeaCache focuses on model inputs, which have a strong correlation with the modeloutputs while incurring negligible computational cost. TeaCache first modulates the noisy inputs using the timestep embeddings to ensure their differences better approximating those of model outputs. TeaCache then introduces a rescaling strategy to refine the estimated differences and utilizes them to indicate output caching. Experiments show that TeaCache achieves up to 4.41x acceleration over Open-Sora-Plan with negligible (-0.07% Vbench score) degradation of visual quality.
PersonalVideo: High ID-Fidelity Video Customization without Dynamic and Semantic Degradation
Nov 26, 2024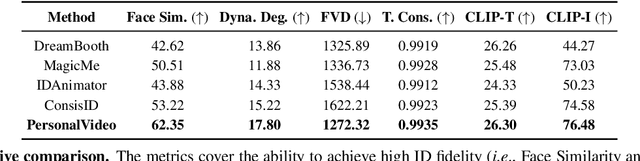
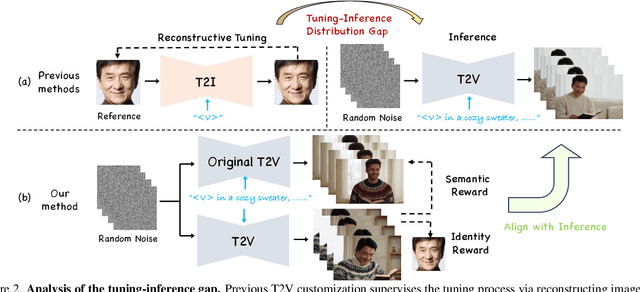
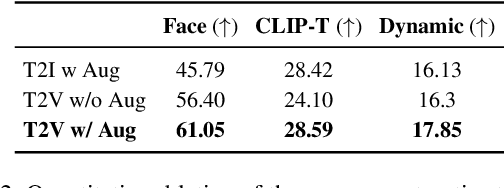
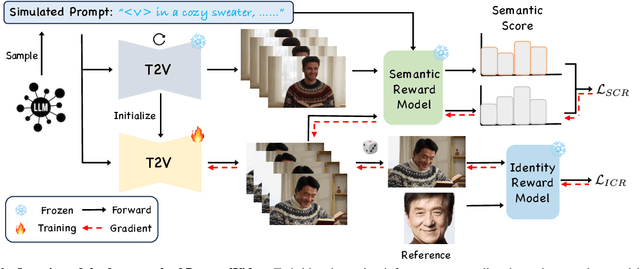
The current text-to-video (T2V) generation has made significant progress in synthesizing realistic general videos, but it is still under-explored in identity-specific human video generation with customized ID images. The key challenge lies in maintaining high ID fidelity consistently while preserving the original motion dynamic and semantic following after the identity injection. Current video identity customization methods mainly rely on reconstructing given identity images on text-to-image models, which have a divergent distribution with the T2V model. This process introduces a tuning-inference gap, leading to dynamic and semantic degradation. To tackle this problem, we propose a novel framework, dubbed \textbf{PersonalVideo}, that applies direct supervision on videos synthesized by the T2V model to bridge the gap. Specifically, we introduce a learnable Isolated Identity Adapter to customize the specific identity non-intrusively, which does not comprise the original T2V model's abilities (e.g., motion dynamic and semantic following). With the non-reconstructive identity loss, we further employ simulated prompt augmentation to reduce overfitting by supervising generated results in more semantic scenarios, gaining good robustness even with only a single reference image available. Extensive experiments demonstrate our method's superiority in delivering high identity faithfulness while preserving the inherent video generation qualities of the original T2V model, outshining prior approaches. Notably, our PersonalVideo seamlessly integrates with pre-trained SD components, such as ControlNet and style LoRA, requiring no extra tuning overhead.